2.1 Context & Motivation#
This book demonstrates scientific workflows using publicly available, cloud-optimized geospatial datasets and open-source scientific software tools in order to address the need for educational resources related to new technologies and reduce barriers to entry to working with earth observation data. The tutorials in this book focus on the complexities inherent to working with n-dimensional, gridded datasets and use the core stack of software packages built on and around the Xarray data model.
Moving away from the ‘download model’ of scientific data analysis#
Technological developments in recent decades have engendered fundamental shifts in the nature of scientific data and how it is used for analysis (Abernathey et al. [1], Gentemann et al. [15], Stern et al. [48]).
“Traditionally, scientific data have been distributed via a “download model,” wherein scientists download individual data files to local computers for analysis. After downloading many files, scientists typically have to do extensive processing and organizing to make them useful for the data analysis; this creates a barrier to reproducibility, since a scientist’s analysis code must account for this unique “local” organization. Furthermore, the sheer size of the datasets (many terabytes to petabytes) can make downloading effectively impossible. Analysis of such data volumes also can benefit from parallel / distributed computing, which is not always readily available on local computers. Finally, this model reinforces inequality between privileged institutions that have the resources to host local copies of the data and those that don’t. This restricts who can participate in science.” – Abernathey et al. [1]
Increasingly large, cloud-optimized data means new tools and approaches for data management#
The increase in publicly available earth observation data has transformed scientific workflows across a range of fields, prompting analysts to gain new skills in order to work with larger volumes of data in new formats and locations, and to use distributed cloud-computational resources in their analysis (Abernathey et al. [1], Boulton [5], Gentemann et al. [15], Martin Sudmanns and Blaschke [37], Mathieu et al. [38], Ramachandran et al. [42], Wagemann et al. [53]).
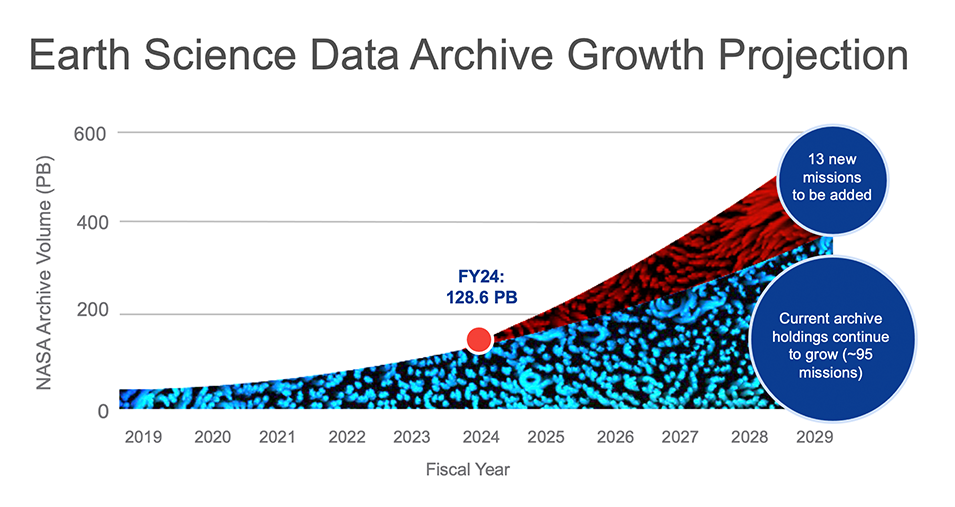
Fig. 1 Volume of NASA Earth Science Data archives, including growth of existing-mission archives and new missions, projected through 2029. Source: NASA EarthData - Open Science.#
Asking questions of complex datasets#
Scientific workflows involve asking complex questions of diverse types of data. Earth observation and related datasets often contain two types of information: measurements of a physical observable (e.g. temperature) and metadata that provides auxiliary information that required in order to interpret the physical observable (time and location of measurement, information about the sensor, etc.). With the increasingly complex and large volume of earth observation data that is currently available, storing, managing and organizing this information can very quickly become a complex and challenging task, especially for students and early-career analysts (Martin Sudmanns and Blaschke [37], Mathieu et al. [38], Palumbo et al. [41], Stern et al. [48], Wagemann et al. [53]).
This book provides detailed examples of scientific workflow steps that ingest complex, multi-dimensional datasets, introduce users to the landscape of popular, actively-maintained open-source software packages for working with geospatial data in Python, and include strategies for working with larger-than memory data stored in publicly available, cloud-hosted repositories. These demonstrations are accompanied by detailed discussion of concepts involved in analyzing earth observation data such as dataset inspection, manipulation, and exploratory analysis and visualization. Overall, we emphasize the importance of understanding the structure of multi-dimensional earth observation datasets within the context of a given data model and demonstrate how such an understanding can enable more efficient and intuitive scientific workflows.